A report on the track “There Is No Here Here”, how the Internet was used as a choir for this track. The video above shows some of the audio elements of the track, and the editing of the voices. The text goes a bit deeper into the details.
Concept
The track was written about a year ago. Its the final song for a performance where I create music videos live on stage, and this is the final track, where it all kind of disappears into “the matrix”, the green of computeres morphs together with the chromakey greenscreen, we end up in a “nowhere”, and the performance ends with a transition to a completely green rave.
 Like many of my recent tracks, this track was created both musically and visually at the same time, so the music incluences the visuals and the visuals influences the music. They both “push and pull” what the track should be while making it.
Like many of my recent tracks, this track was created both musically and visually at the same time, so the music incluences the visuals and the visuals influences the music. They both “push and pull” what the track should be while making it.
The visuals for this video has the basic ideo of “retro computing, coding, hacking”, not necessarily vaporwave, but there is a lot of oldskool wireframe graphics, early net and 90ioes cyber graphics, all put together in a mashup of old computer operating systems. For the music, I wanted to create an oldskool techno track that also referenced the same kind of “era”, early 90ies techno, kind of dark hacker techno.

Structure
Ugress tracks often have a pop-based song structure with a sort of block-based build and open dynamics in energy, but for this one its a pure one-directional buildup, kind of stepping up to plateau after plateau and never “resting”. The live version is much longer than the album version, with a very long intro and middle, because there are parts that need a lot of visual focus in the live version, and then I hold back on musical development. For the album release I shortened these parts quite drastically.
Music and sound design
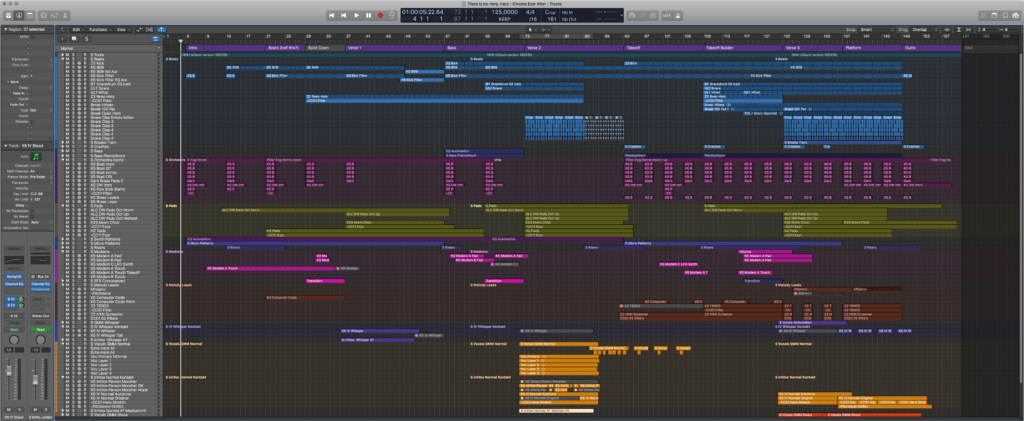 A few words on music and sound design. I think generally, its the sound design, rhythmical elements and sense of energy, urgency that carries this song I think, not so much the musical depth. Which is typical for techno, really. The bass parts are very busy, but also very simplistic, made by several plugins, they play static patterns that are modulated in and out of “depth”, they stay in the same key all the way, giving it a kind of drone-ish, dystopian presence.
A few words on music and sound design. I think generally, its the sound design, rhythmical elements and sense of energy, urgency that carries this song I think, not so much the musical depth. Which is typical for techno, really. The bass parts are very busy, but also very simplistic, made by several plugins, they play static patterns that are modulated in and out of “depth”, they stay in the same key all the way, giving it a kind of drone-ish, dystopian presence.
Above this bedrock there are a bunch of synth and sample-based microsound lines, building up more of a texture than a melody really, and then for the “chorus” parts, the pads are the first real musical element, gently shifting between four chords that all work with same bass note. Half-way through the track, a screaming synthesizer plays a repeated pattern in the same vein as the bass lines, and its the modulation of sound texture that provides sonic interest, not the notes themselves. The vocals repeat a pretty simple patterned melody with small variations.
Internet Choir
The special thing with this track, is of course, the incredible Internet Choir!
In the live version I was the vocalist, heavily processed, but now for the album version I really wasn’t sure to use my own or an external vocalist, and the idea of a “pretty singer” like much of the early 90ies pop techno was obvious…. but didn’t feel quite right. I was talking about this with Jarle at my distributor Phonofile, and he reminded me “find the voice that is right for the concept of the song”, and just a few days later it popped into my head out of the blue – of course, the Internet should be the voice of this song.
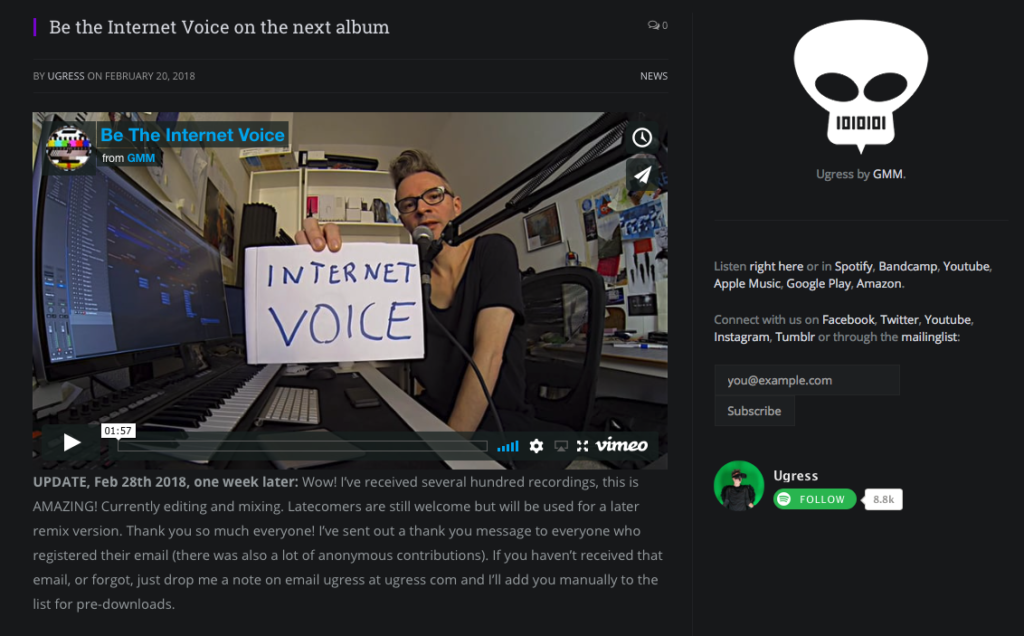 I created a post on the Ugress website, with a simple but brilliant widget from SpeakPipe that allowed for instant recording for any visitor, and also made it possible to email or text me voice messages, and posted this on the website, the mailinglist and in social media. After a week I had around 200 contributions, many of them with three different versions, and several sending a whole bunch of takes. By far the widget was the most popular, I think maybe 80% participated through the widget, maybe 10-15% sent me emails, and a small percentage sent whatsapp or telegram messages.
I created a post on the Ugress website, with a simple but brilliant widget from SpeakPipe that allowed for instant recording for any visitor, and also made it possible to email or text me voice messages, and posted this on the website, the mailinglist and in social media. After a week I had around 200 contributions, many of them with three different versions, and several sending a whole bunch of takes. By far the widget was the most popular, I think maybe 80% participated through the widget, maybe 10-15% sent me emails, and a small percentage sent whatsapp or telegram messages.
 So I had around 200 files of very different material. It was hilarious to listen to all of it – and it was also very moving, I was actually quite touched by the sweetness of all the contributions. it was very special to be editing each voice, this was of all things a very humbling experience. I have always had huge respect and awe that I have such great fans, but now it was like they – you! – suddenly appear as real, human entities, with voices and personalities, INSIDE my work, and I am reminded that we are all, both creators and listeners, very complex beings, and not just a website, an email address, a Bandcamp payment, a social media profile or a face that appears in a music video or in the crowd at live shows.
So I had around 200 files of very different material. It was hilarious to listen to all of it – and it was also very moving, I was actually quite touched by the sweetness of all the contributions. it was very special to be editing each voice, this was of all things a very humbling experience. I have always had huge respect and awe that I have such great fans, but now it was like they – you! – suddenly appear as real, human entities, with voices and personalities, INSIDE my work, and I am reminded that we are all, both creators and listeners, very complex beings, and not just a website, an email address, a Bandcamp payment, a social media profile or a face that appears in a music video or in the crowd at live shows.
This was really special and I am extremely grateful for the voices, I LOVE editing them, it took several days, and I treated every single one with concentration and care. Everybody who contributed (before March 6th when I had to deliver the master), is in the song, NOTHING was deleted, I even used RX to clean up and fix a few broken and noisy recordings. Any latecomers will be in a remix version coming later this year.
But I was actually quite surprised how extremely usable almost every contribution was – it was all quiet, clear recordings that could be used directly without any problem. Its quite amazing how easy it was to pull of this, either the quality of “average consumer tech audio recording” or the sheer talent of everybody participating 😉
There was an interesting issue I hadn’t thought of – almost all recordings had been psycho-acoustically compressed, to save on file size, either as mp3 or aac, and that is generally not noticable for a single recording. But when layering hundreds of these encoded recordings, the artifacts of the encoding process add up, and they give the sum mix a kind of “glossy” cloudish property, like the whole thing lacks some kind of substance, but you can “hear” it – like the shimmering in Annihilation, its there, or not there, it affects you but hard to define? Quite quite interesting, I’d love to do a deeper project on this “nothingness” that appears in the sum-of-parts when you add up compressed material from the internet.
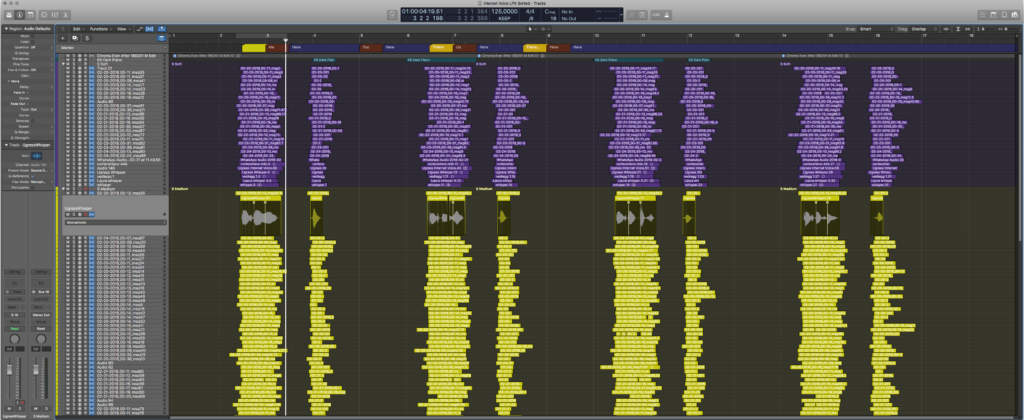
Editing the voices
I put all of these files into Logic Pro, and spent two days organizing, grouping, classifying and syncing everyone up so their timing would be sort of the same. I split everything into three groups; soft whispery contributions, normal contributions and shouty contributions. I did foresee that timing everyone would be a lot of work, and thought about giving stronger directions, possibly also melody and a reference clicktrack for sending in the contribution, but that would make it too complicated, I decided to rather make the threshold for participating as low as possible, let people deliver it any way they wanted. Technology can do the “heavy lifting” of making sure everyone was in time and in key.
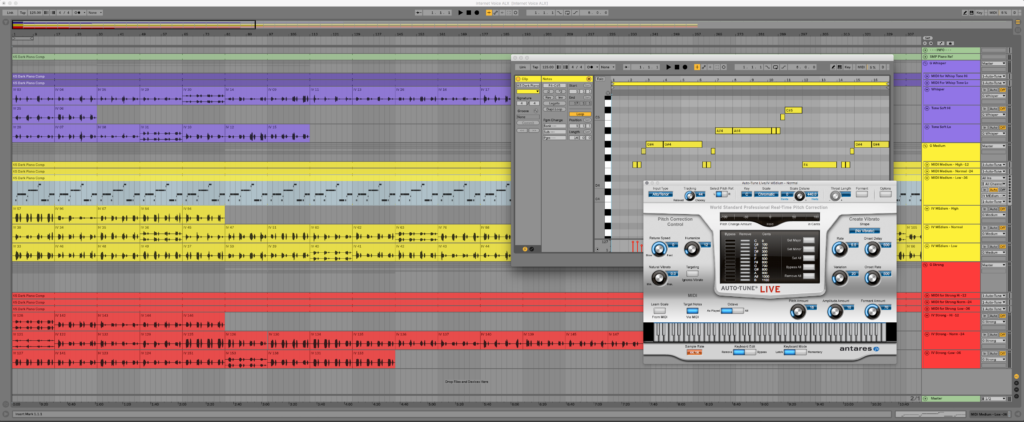
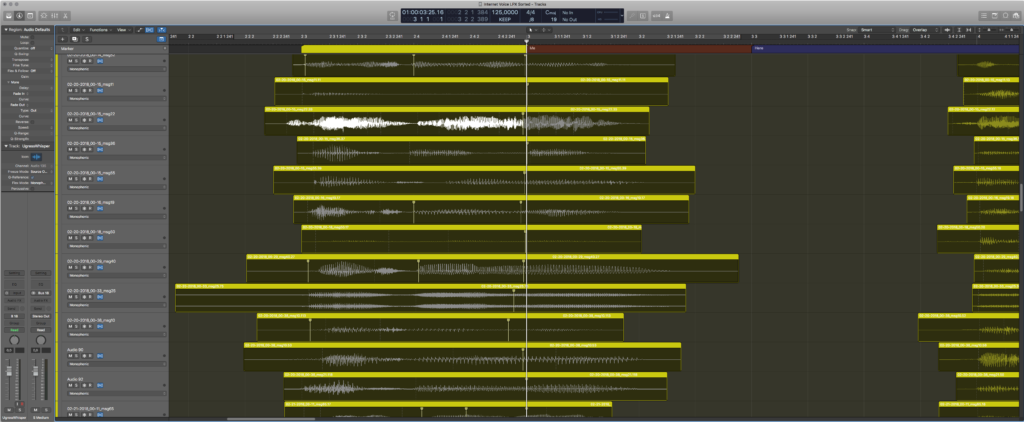 In the screenshot above, all the “me”s in “there’s no me, here” are roughly aligned to sync up at the downbeat, at the main cursor horizontal line. I tried to keep the timing of voices loose enough to be a crowd of individuals, but tight enough to hear the diction of each word.
In the screenshot above, all the “me”s in “there’s no me, here” are roughly aligned to sync up at the downbeat, at the main cursor horizontal line. I tried to keep the timing of voices loose enough to be a crowd of individuals, but tight enough to hear the diction of each word.
Once I had every voice synced up, I could then export all tracks as equal lengths, and I set up a simple system in Ableton Live to autotune every single individual. Since every block of audio was the same length, this was just to set it up once, and then loop the MIDI segments that forces autotune to “correct” to a specific note, and let the computer do the work while I sip coffee. People tended to be in one of three octaves, so I sorted and processed them slightly different depending on on their octave, ending up with a matrix of 9 different “choirs”.
 For each of these choirs I then loaded every single individual voice into Kontakt, a software sampler, which has an okay elastic time algorithm, which then allowed me to actually stretch and manipulate each invidividual voice in realtime, as a group. This was something I needed for musical purpose in the tail ends of phrases, and for some sound design purposes towards the end of the track, to create these long, monstrous “hereeeeeeeee”’s.
For each of these choirs I then loaded every single individual voice into Kontakt, a software sampler, which has an okay elastic time algorithm, which then allowed me to actually stretch and manipulate each invidividual voice in realtime, as a group. This was something I needed for musical purpose in the tail ends of phrases, and for some sound design purposes towards the end of the track, to create these long, monstrous “hereeeeeeeee”’s.
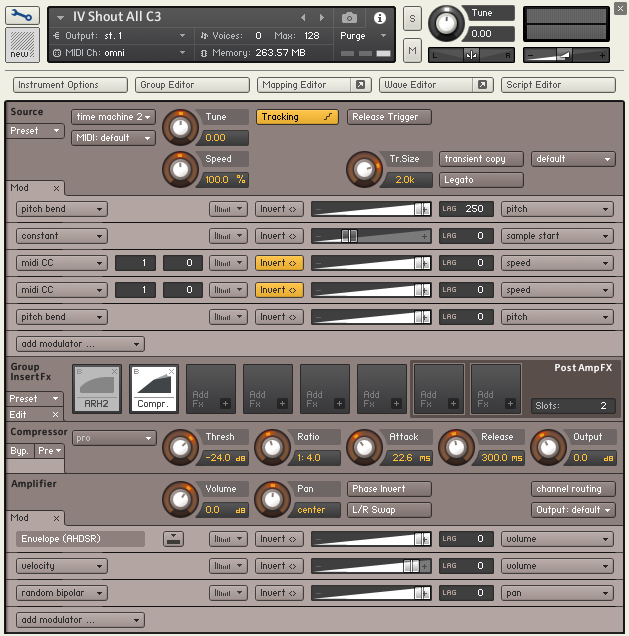
Another reason for using a sampler is that I can manipulate and process multiple voices as either a group or individually in realtime, like EQ, compression, filters, and its also way easier to introduce random elements like pan, volume, pitch to each voice, so the whole group feels more “alive”. This would be tedious to set up and make continous adjustments to with hundreds of audio tracks. For the chorus in the middle part of the song, I set up a randomization system that would let single voices “pop” out at random moments, so it would be possible to recognize individual voices. This happens randomly for each playthrough, of course in the frozen album version it is frozen like it is, but every live performance will have a different set of individuals being prominent in the mix.
Now I had all individual voices in their right timing, and both in original and in auto-tuned melodic versions. From here it was just a “fit the puzzle pieces together”, balancing and mixing all the elements, creating the right “mix” and atmosphere.
For the first chorus, it consists mostly of the original whispery versions, with my voice being the main element with a melody, though the autotuned whisper versions are still there, very quiet. For the second chorus, I use both the normal spoken versions and the autotuned melody versions of those, to give it a larger but musical presence, together with overdubs of my own voice. And for the third and final chorus and the outtro, I use the much of the same as the second, but also add the whispers, and add all the shouty versions, with their autotune parts some and additional “processed” choir on top of that for the monstrous layers. So I think for the last chorus, there is probably more than 1000 voices at the same time (approx 200 individuals x 3 levels x 2 versions (autotune/normal) = 1200) which is fantastic. And they all sing it perfect, every time we play! Good work, Internet!
After having all the elements in place, and the structure locked down, it took maybe two-three days of mixing to get an okay balance. This is where all the small details and effects are added, filling in the blanks. Since this is a track where elements are just continuously added on top of each other, it gest busier and busier, there is quite a bit of EQing on the submixes (a submix is a group of tracks, like all the beats are one submix, all the bass is one, all voices is one etc) to make room for each new element, and for pulling the different elements “in” and “out” of focus.
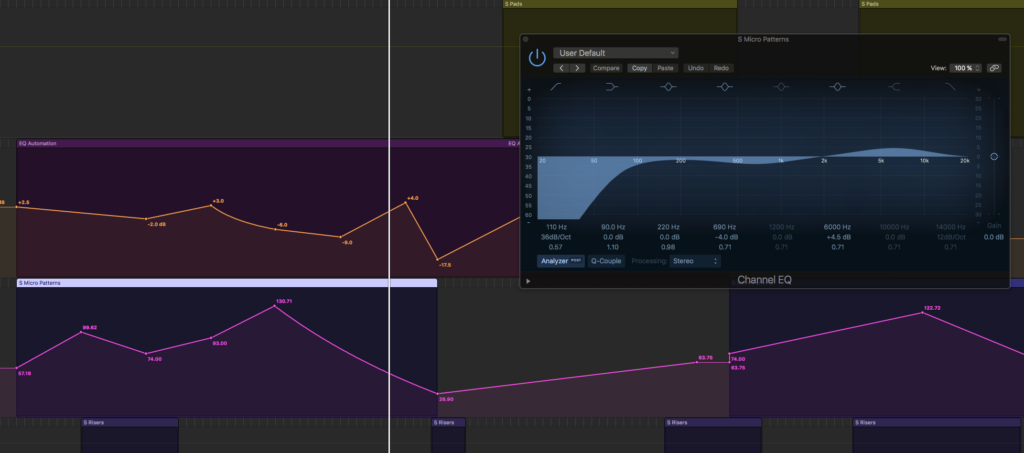 As the screenshot above shows, two submixes are gliding in and out of focus by boosting or reducing their most prominent frequencies. There is also quite a lot of sidechain compression from the beats to all the other parts, a system where beats will automatically push the levels of everything else down, that creates this very contemporary pumping, sucking sound. Especially the bass, pads and orchestra are heavily sidechain compressed, the synths and vocals not so much. This track has bit stronger sidechain compression than I usually prefer, but when I tried to dial it back to sensible levels, the track lost some urgency, so I kept it at mad levels.
As the screenshot above shows, two submixes are gliding in and out of focus by boosting or reducing their most prominent frequencies. There is also quite a lot of sidechain compression from the beats to all the other parts, a system where beats will automatically push the levels of everything else down, that creates this very contemporary pumping, sucking sound. Especially the bass, pads and orchestra are heavily sidechain compressed, the synths and vocals not so much. This track has bit stronger sidechain compression than I usually prefer, but when I tried to dial it back to sensible levels, the track lost some urgency, so I kept it at mad levels.
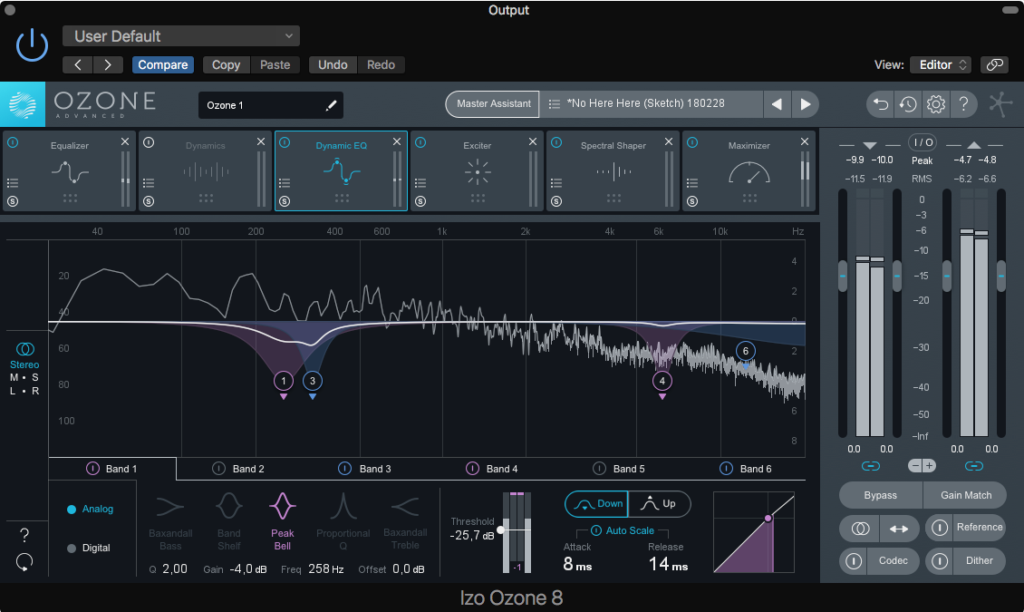 And then at the very end the track is mastered, which takes another half day or so by itself, but to me mastering is not a “finite” step, its an elastic process – towards the end of mixing I start working with the mastering tools simultaenously, kind of “mixing into the master”, so I can go a bit back and forth – the mastering process often identifies problems that are better fixed in the mix, and I like being able to balance both mix and master at the same time for a while.
And then at the very end the track is mastered, which takes another half day or so by itself, but to me mastering is not a “finite” step, its an elastic process – towards the end of mixing I start working with the mastering tools simultaenously, kind of “mixing into the master”, so I can go a bit back and forth – the mastering process often identifies problems that are better fixed in the mix, and I like being able to balance both mix and master at the same time for a while.
But the final master is done purely as a master, with a locked mix, and thats mostly “polish”. I’m very fond of Izotope’s Ozone, that uses AI and machine learning to help analyze the track and suggest subtle improvements and adjustments. The final master is not really far from the final mix, I would say its just “cleaned” up, a little polish to control unruly frequencies, and normalized to digital relase levels.
Conclusion

Expedtion success. I am quite happy with the track! Perhaps a bit more as a live track than a released track, but that might be because its so great fun to perform this track, the power and energy and “drama” comes to its full life on loud sound system and dark stage and blinking lights, and it does make quite a bit more “sense” with the visuals.
I am not one thousand percent satisfied with the beats, they work extremely well live, but I think they’re a bit too naked for album, but its a tradeoff. And I wanted to keep them very 90ies. I’m very happy with the energy and “dramatization” of the track, I really like how it builds.
But what I like best about this track, of course, is YOU, the Internet choir. It was so fun to work with this! To edit everyones voices was a very touching and rewarding experience. Really looking forward to figure out how to pull this off live and bring the Internet with me on stage.


